
TL;DR:
- We introduce Teachable Agents so that users can teach their LLM-based assistants new facts, preferences, and skills.
- We showcase examples of teachable agents learning and later recalling facts, preferences, and skills in subsequent chats.
Introduction
Conversational assistants based on LLMs can remember the current chat with the user, and can also demonstrate in-context learning of user teachings during the conversation. But the assistant's memories and learnings are lost once the chat is over, or when a single chat grows too long for the LLM to handle effectively. Then in subsequent chats the user is forced to repeat any necessary instructions over and over.
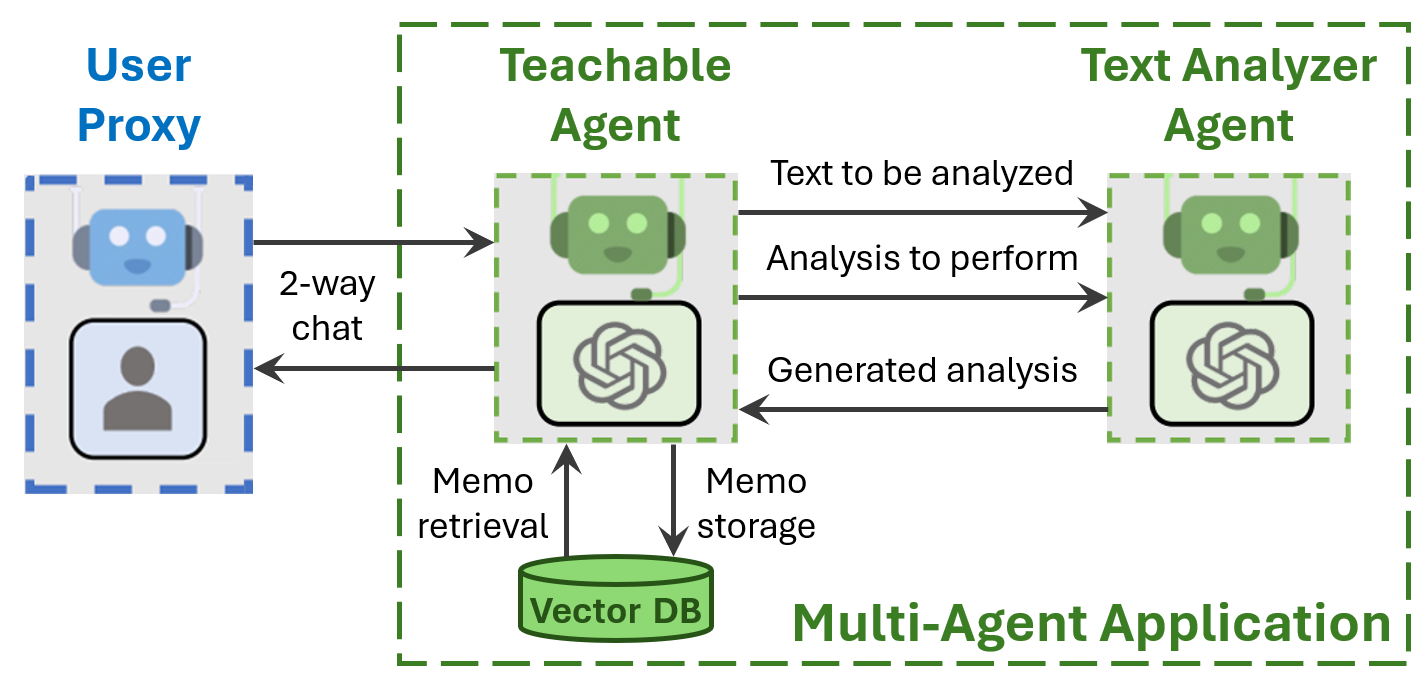
Teachability addresses these limitations by persisting user teachings across chat boundaries in long-term memory implemented as a vector database. Instead of copying all of memory into the context window, which would eat up valuable space, individual memories (called memos) are retrieved into context as needed. This allows the user to teach frequently used facts and skills to the teachable agent just once, and have it recall them in later chats.
Any instantiated agent that inherits from ConversableAgent can be made teachable by instantiating a Teachability object and calling its add_to_agent(agent) method.
In order to make effective decisions about memo storage and retrieval, the Teachability object calls an instance of TextAnalyzerAgent (another AutoGen agent) to identify and reformulate text as needed for remembering facts, preferences, and skills. Note that this adds extra LLM calls involving a relatively small number of tokens, which can add a few seconds to the time a user waits for each response.
Run It Yourself
AutoGen contains four code examples that use Teachability.
-
Run chat_with_teachable_agent.py to converse with a teachable agent.
-
Run test_teachable_agent.py for quick unit testing of a teachable agent.
-
Use the Jupyter notebook agentchat_teachability.ipynb to step through examples discussed below.
-
Use the Jupyter notebook agentchat_teachable_oai_assistants.ipynb to make arbitrary OpenAI Assistants teachable through
GPTAssistantAgent.
Basic Usage of Teachability
- Install dependencies
Please install autogen with the [teachable] option before using Teachability.
pip install "autogen[teachable]"
- Import agents
from autogen import UserProxyAgent, config_list_from_json
from autogen.agentchat.contrib.capabilities.teachability import Teachability
from autogen import ConversableAgent # As an example
- Create llm_config
# Load LLM inference endpoints from an env variable or a file
# See https://autogenhub.github.io/autogen/docs/FAQ#set-your-api-endpoints
# and OAI_CONFIG_LIST_sample
filter_dict = {"model": ["gpt-4"]} # GPT-3.5 is less reliable than GPT-4 at learning from user feedback.
config_list = config_list_from_json(env_or_file="OAI_CONFIG_LIST", filter_dict=filter_dict)
llm_config={"config_list": config_list, "timeout": 120}
- Create the agents
# Start by instantiating any agent that inherits from ConversableAgent, which we use directly here for simplicity.
teachable_agent = ConversableAgent(
name="teachable_agent", # The name can be anything.
llm_config=llm_config
)
# Instantiate a Teachability object. Its parameters are all optional.
teachability = Teachability(
reset_db=False, # Use True to force-reset the memo DB, and False to use an existing DB.
path_to_db_dir="./tmp/interactive/teachability_db" # Can be any path, but teachable agents in a group chat require unique paths.
)
# Now add teachability to the agent.
teachability.add_to_agent(teachable_agent)
# For this test, create a user proxy agent as usual.
user = UserProxyAgent("user", human_input_mode="ALWAYS")
- Chat with the teachable agent
# This function will return once the user types 'exit'.
teachable_agent.initiate_chat(user, message="Hi, I'm a teachable user assistant! What's on your mind?")
Example 1 - Learning user info
A user can teach the agent facts about themselves. (Note that due to their finetuning, LLMs can be reluctant to admit that they know personal information.)
Loading previous memory (if any) from disk.
Greetings, I'm a teachable user assistant! What's on your mind today?
--------------------------------------------------------------------------------
Provide feedback to teachable_agent. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: My name is Ricky
My name is Ricky
--------------------------------------------------------------------------------
>>>>>>>> USING AUTO REPLY...
Hello Ricky! How can I assist you today?
--------------------------------------------------------------------------------
Provide feedback to teachable_agent. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: exit
In a later conversation, the user can check whether the teachable agent remembers their name. (For readability, the user prompts and some logged notices are not repeated below.)
--------------------------------------------------------------------------------
what's my name?
--------------------------------------------------------------------------------
Hi Ricky! How can I help you today?
--------------------------------------------------------------------------------
Example 2 - Learning new facts
A user can teach the agent more complex, related facts.
--------------------------------------------------------------------------------
What is the Vicuna model?
--------------------------------------------------------------------------------
I'm sorry, but I don't have information about the "Vicuna model" in my current database. Could you please provide some context, description, or details about this model so I can better assist you?
--------------------------------------------------------------------------------
Vicuna is a 13B-parameter language model released by Meta.
--------------------------------------------------------------------------------
Thank you for providing the information. The Vicuna model is a large-scale language model developed by Meta. It consists of 13 billion parameters, which is what makes it able to understand and generate human-like text across various topics. Parameters in a neural network are the weights and biases assigned to each connection between the neurons, and having more parameters enables the model to learn and capture more complex patterns and relationships in data. As an AI language model, Vicuna can be utilized in various language-related tasks, such as text completion, translation, summarization, and more.
--------------------------------------------------------------------------------
What is the Orca model?
--------------------------------------------------------------------------------
The Orca model is a yet-to-be-released language model by Meta, referring to the Research Preview API release of Meta's advanced language model. While I don't have specific details about the Orca model at this time, it is expected that the model would have an even larger number of parameters to further enhance its capabilities compared to its predecessor, Vicuna.
As AI language models evolve, they generally become more efficient at understanding and generating human-like text. This makes them more effective in completing a wide range of tasks, including text completion, translation, summarization, and Q&A, as well as providing more accurate and coherent results in various applications.
--------------------------------------------------------------------------------
Orca is a 13B-parameter language model released by Microsoft. It outperforms Vicuna on most tasks.
--------------------------------------------------------------------------------
Thank you for the clarification. Orca is a 13-billion-parameter language model developed by Microsoft. It is designed to outperform Vicuna, the language model released by Meta. With a large number of parameters, Orca is capable of understanding and generating human-like text across diverse subjects, making it highly useful in various applications.
Orca's advanced capabilities allow it to excel in tasks such as text completion, translation, summarization, Q&A, and more. Its performance improvement over Vicuna highlights the rapid advancements in natural language processing (NLP) research and the development of increasingly capable AI language models.
Then in a later chat the teachable agent can answer questions about the facts it has been taught. (Remember to first close the previous chat by typing 'exit'.)
--------------------------------------------------------------------------------
How does the Vicuna model compare to the Orca model?
--------------------------------------------------------------------------------
The Vicuna and Orca models are both 13B-parameter language models released by Meta and Microsoft, respectively. In terms of performance, Orca has been reported to outperform Vicuna on most tasks. However, without detailed information about specific tasks and benchmarks, it is difficult to provide a more comprehensive comparison. Generally speaking, both models are advanced language models that aim to provide high-quality natural language understanding and generation, but Orca appears to have an edge in terms of overall performance.
--------------------------------------------------------------------------------
Example 3 - Learning user preferences
A user can teach the agent how they prefer to have things done.
Be aware that a message like the next one cannot be entered as a single message through a command line because it contains a newline character. Such messages can be entered in a Jupyter notebook, or through some UI layer like that of ChatGPT.
--------------------------------------------------------------------------------
Please summarize this abstract.
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, Chi Wang
AutoGen is an open-source framework that allows developers to build LLM applications via multiple agents that can converse with each other to accomplish tasks. AutoGen agents are customizable, conversable, and can operate in various modes that employ combinations of LLMs, human inputs, and tools. Using AutoGen, developers can also flexibly define agent interaction behaviors. Both natural language and computer code can be used to program flexible conversation patterns for different applications. AutoGen serves as a generic infrastructure to build diverse applications of various complexities and LLM capacities. Empirical studies demonstrate the effectiveness of the framework in many example applications, with domains ranging from mathematics, coding, question answering, operations research, online decision-making, entertainment, etc.
--------------------------------------------------------------------------------
AutoGen is an open-source framework designed to enable developers to create LLM applications with multiple customizable agents that can converse with each other to complete tasks. These agents can operate using different combinations of LLMs, human inputs, and tools, allowing developers to define agent interaction behaviors flexibly. AutoGen supports programming flexible conversation patterns using both natural language and code, making it suitable for building diverse applications with varying complexities and LLM capacities. Its effectiveness has been demonstrated through empirical studies across various domains including mathematics, coding, operations research, decision-making, and entertainment.
--------------------------------------------------------------------------------
Please summarize this abstract. When I'm summarizing an abstract, I try to make the summary contain just three short bullet points: the title, the innovation, and the key empirical results.
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, Chi Wang
AutoGen is an open-source framework that allows developers to build LLM applications via multiple agents that can converse with each other to accomplish tasks. AutoGen agents are customizable, conversable, and can operate in various modes that employ combinations of LLMs, human inputs, and tools. Using AutoGen, developers can also flexibly define agent interaction behaviors. Both natural language and computer code can be used to program flexible conversation patterns for different applications. AutoGen serves as a generic infrastructure to build diverse applications of various complexities and LLM capacities. Empirical studies demonstrate the effectiveness of the framework in many example applications, with domains ranging from mathematics, coding, question answering, operations research, online decision-making, entertainment, etc.
--------------------------------------------------------------------------------
- Title: AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
- Innovation: Open-source framework for creating customizable LLM applications through agent conversations, supporting various modes and interaction behaviors.
- Key Empirical Results: Demonstrated effectiveness across diverse application domains, including mathematics, coding, question answering, and more.
--------------------------------------------------------------------------------
Then in later chats the teacher doesn't need to reiterate their detailed preferences.
--------------------------------------------------------------------------------
Please summarize this abstract.
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, Yi Zhang
Artificial intelligence (AI) researchers have been developing and refining large language models (LLMs) that exhibit remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. The latest model developed by OpenAI, GPT-4, was trained using an unprecedented scale of compute and data. In this paper, we report on our investigation of an early version of GPT-4, when it was still in active development by OpenAI. We contend that (this early version of) GPT-4 is part of a new cohort of LLMs (along with ChatGPT and Google's PaLM for example) that exhibit more general intelligence than previous AI models. We discuss the rising capabilities and implications of these models. We demonstrate that, beyond its mastery of language, GPT-4 can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting. Moreover, in all of these tasks, GPT-4's performance is strikingly close to human-level performance, and often vastly surpasses prior models such as ChatGPT. Given the breadth and depth of GPT-4's capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system. In our exploration of GPT-4, we put special emphasis on discovering its limitations, and we discuss the challenges ahead for advancing towards deeper and more comprehensive versions of AGI, including the possible need for pursuing a new paradigm that moves beyond next-word prediction. We conclude with reflections on societal influences of the recent technological leap and future research directions.
--------------------------------------------------------------------------------
- Title: Sparks of Artificial General Intelligence: Early experiments with GPT-4
- Innovation: GPT-4, an LLM with remarkable capabilities, demonstrates human-level performance across various domains, like math, coding, vision, medicine, law, and psychology.
- Key results: GPT-4 significantly surpasses prior models, suggesting it may be an early version of AGI; limitations and challenges toward deeper AGI are also discussed.
--------------------------------------------------------------------------------
Example 4 - Learning new skills
Users can extend the teachable agent's capabilities by teaching it new skills for accomplishing challenging tasks. It usually works best to first describe the task, then (in the same turn) provide a hint or advice for approaching the task.
The Sparks of AGI paper evaluated GPT-4 on math problems like the following, which it could only solve 32% of the time. We first show a failure case, then teach the agent a strategy which lifts GPT-4's success rate above 95%.
--------------------------------------------------------------------------------
Consider the identity:
9 * 4 + 6 * 6 = 72
Can you modify exactly one integer (and not more than that!) on the left hand side of the equation so the right hand side becomes 99?
-Let's think step-by-step, write down a plan, and then write down your solution as: "The solution is: A * B + C * D".
--------------------------------------------------------------------------------
Step 1: Identify the current equation and the target value on the right-hand side.
Current equation: 9 * 4 + 6 * 6 = 72
Target value: 99
Step 2: Determine what numbers can be changed on the left-hand side.
Possible changes: 9, 4, 6 (first occurrence), and 6 (second occurrence)
Step 3: Evaluate whether each change in the numbers on the left-hand side can result in the target value.
9 -> If changed, it would create a larger product.
4 -> If changed, the product would increase or decrease by more than the amount needed to reach 99.
6 (first occurrence) -> If increased to 7, then the equation would be 9 * 4 + 7 * 6 = 94, which is still not 99.
6 (second occurrence) -> If increased to 7, then the equation would be 9 * 4 + 6 * 7 = 99.
Step 4: Write down the solution.
The solution is: 9 * 4 + 6 * 7
--------------------------------------------------------------------------------
Consider the identity:
9 * 4 + 6 * 6 = 72
Can you modify exactly one integer (and not more than that!) on the left hand side of the equation so the right hand side becomes 99?
-Let's think step-by-step, write down a plan, and then write down your solution as: "The solution is: A * B + C * D".
Here's some advice that may help:
1. Let E denote the original number on the right.
2. Let F denote the final number on the right.
3. Calculate the difference between the two, G = F - E.
4. Examine the numbers on the left one by one until finding one that divides evenly into G, where negative integers are allowed.
5. Calculate J = G / H. This is the number of times that H divides into G.
6. Verify that J is an integer, and that H * J = G.
7. Find the number on the left which is multiplied by H, and call it K.
8. Change K to K + J.
9. Recompute the value on the left, and verify that it equals F.
Finally, write down your solution as: "The solution is: A * B + C * D".
--------------------------------------------------------------------------------
Step 1: Identify the original number (E) and the final number (F) on the right-hand side.
E = 72
F = 99
Step 2: Calculate the difference between the two, G = F - E.
G = 99 - 72 = 27
Step 3: Examine the numbers on the left one by one until finding one that divides evenly into G, where negative integers are allowed.
9 (divides evenly into 27)
4 (does not)
6 (first occurrence, does not)
6 (second occurrence, does not)
Step 4: Calculate J = G / H. This is the number of times that H divides into G.
H = 9 (since 9 divides evenly into 27)
J = 27 / 9 = 3
Step 5: Verify that J is an integer, and that H * J = G.
H * J = 9 * 3 = 27
J = 3 (which is an integer)
Step 6: Find the number on the left which is multiplied by H, and call it K.
Number on the leftside of the equation that is multiplied by 9: 4
Therefore, K = 4
Step 7: Change K to K + J.
K + J = 4 + 3 = 7
Step 8: Recompute the value on the left, and verify that it equals F.
9 * 7 + 6 * 6 = 63 + 36 = 99 (which is equal to F)
Step 9: Write down the solution.
The solution is: 9 * 7 + 6 * 6
--------------------------------------------------------------------------------
In a later chat the user doesn't need to repeat the detailed advice.
--------------------------------------------------------------------------------
Consider the identity:
8 * 3 + 7 * 9 = 87
Can you modify exactly one integer (and not more than that!) on the left hand side of the equation so the right hand side becomes 59?
-Let's think step-by-step, write down a plan, and then write down your solution as: "The solution is: A * B + C * D".
--------------------------------------------------------------------------------
Let's follow the advice to modify one integer on the left hand side of the equation to make the right hand side become 59:
1. Let E denote the original number on the right: E = 87.
2. Let F denote the final number on the right: F = 59.
3. Calculate the difference between the two, G = F - E: G = 59 - 87 = -28.
4. Examine the numbers on the left one by one to find one that divides evenly into G: 8, 3, 7, 9. Since 7 divides -28 evenly, we will work with 7 (H = 7).
5. Calculate J = G / H: J = -28 / 7 = -4.
6. Verify that J is an integer, and that H * J = G: J is an integer, and 7 * (-4) = -28.
7. Find the number on the left which is multiplied by H (7), and call it K: K = 9.
8. Change K to K + J: K_new = 9 + (-4) = 5.
9. Recompute the value on the left, and verify that it equals F: (8 * 3) + (7 * 5) = 24 + 35 = 59.
The solution is: 8 * 3 + 7 * 5
--------------------------------------------------------------------------------
Planned improvements
- Understanding user instructions distributed over multiple turns.
- Learning from the agent's own experience, to reduce dependence on explicit user teachings.
- Learning skills built on top of previously learned skills.
Conclusion
Teachability is still under active research and development. For any problems you find or improvements you have in mind, please join our discussions in this repo and on our Discord channel. We look forward to seeing how you and the rest of the community can use and improve teachable agents in AutoGen!