In today’s fast-paced GenAI landscape, organizations are constantly searching for smarter, more efficient ways to manage and transform data. Nexla is a platform dedicated to the automation of data engineering, enabling users to get ready-to-use data with minimal hassle. Central to Nexla’s approach are Nexsets—data products that streamline the process of integrating, transforming, delivering, and monitoring data. Our mission is to make data ready-to-use for everyone, eliminating the complexities traditionally associated with data workflows.
With the introduction of Project NOVA, we’re leveraging Autogen, an open-source project initialized by Microsoft and multiple academia institutions, to create powerful, production-grade agentic workflows that empower users to accomplish complex tasks with the simplicity of natural language.
The Challenge: Elevating Data Automation at Nexla
One of the primary challenges our customers face is the time and effort required to develop and manage complex data transformations. Even with a clear vision of the final data model, data transformation is a multi-step process that can be both time-consuming and technically demanding.
The Solution: Harnessing Autogen for Project NOVA
Autogen provided us with the perfect foundation to build intelligent agents capable of handling complex data tasks far beyond basic conversational functions. This led to the creation of NOVA—Nexla Orchestrated Versatile Agents, a system designed to translate natural language into precise data transformations. NOVA simplifies data operations by breaking down complex tasks into manageable steps, enabling users to interact with their data intuitively and efficiently.
By leveraging GenAI Agents built with Autogen, we’ve also tackled the challenge of creating a common data model, allowing for seamless integration of diverse data sources to a unified data model. This innovation bridges the gap between user intent and data manipulation, paving the way for a unified and accessible data infrastructure across platforms and industries.
Natural Language to Transforms
NOVA’s Natural Language to Transforms feature allows users to take a Nexset—a data product within Nexla—and describe, in plain language, the transformation they need. NOVA then automatically generates the required transforms, whether in Python or SQL, depending on the task.
For example, a user could simply instruct, "Compute average speed and average duration for every origin-destination pair, hourly and by day of the week." NOVA breaks down this request into a series of steps, applies the necessary transformations, and delivers the desired output. This allows users to focus on analyzing and utilizing the transformed data without getting bogged down in the complexities of coding.
Natural Language to ELT (Extract, Load and Transform)
Next up is Natural Language to ELT, which allows users to build and execute ELT pipelines simply by providing natural language instructions. Users can input one or more Nexsets, a final data model, and an optional set of instructions, and NOVA does the rest.
NOVA doesn’t just generate a static script—it allows users to interactively tweak the SQL logic as they go, ensuring that the final output is exactly what they need. This interactive, dynamic approach makes it easier than ever to handle complex ELT tasks, directly executing business logic on platforms like BigQuery or Snowflake and many other connectors that Nexla supports with precision and efficiency.
Use Cases: Empowering Diverse Users
These features are designed with a broad range of users in mind:
- Data Engineers: Automate routine data transformation tasks, freeing up time to focus on more strategic initiatives.
- Business Analysts: Generate insights quickly without the need for complex coding, enabling faster decision-making.
- Business Users: Interact with data naturally, transforming ideas into actionable queries without requiring deep technical expertise.
Why Nexla and Autogen?
Nexla’s unique value proposition is its ability to integrate advanced AI-driven automation into existing workflows seamlessly. By building on the robust capabilities of Autogen, we’ve ensured that NOVA is not only scalable but also reliable for production-grade applications. The flexibility and power of Autogen have been instrumental in allowing us to create agents that handle sophisticated tasks beyond basic interactions, making them an essential part of our platform’s evolution.
Moreover, the scalability and reliability of Autogen have enabled us to deploy these features across large datasets and cloud platforms, ensuring consistent performance even under demanding workloads.
Technical Deep Dive: The Architecture Behind NOVA
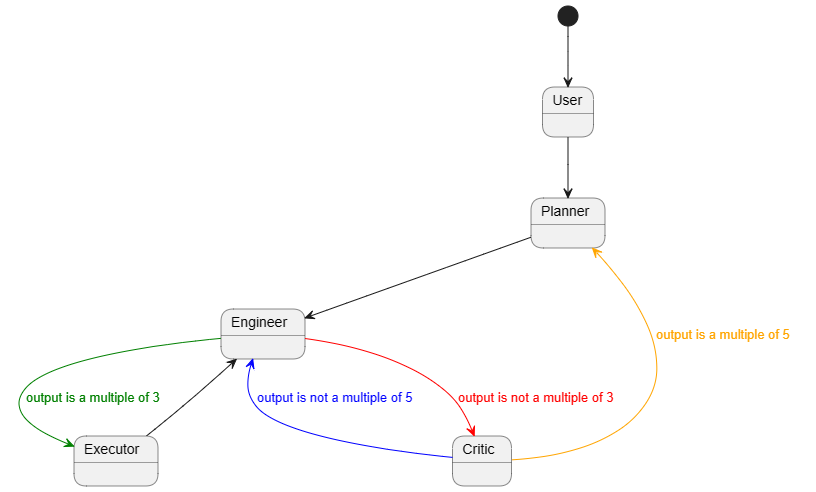
At the heart of NOVA’s success is a sophisticated agent architecture, powered by Autogen:
- Planner Agent: Analyzes user queries to determine the necessary steps for the ELT or transformation task, planning the workflow.
- Query Interpreter Agent: Translates the planner’s high-level steps into actionable SQL or Python for execution by the Data Transformer Agent.
- Data Transformer Agent: Generates the required SQL or Python logic, ensuring it aligns with the specific schema and data samples.
- Evaluator Agent: Reviews the generated logic for accuracy before execution, ensuring it meets the necessary requirements.
- API Agent: Manages interactions with databases and cloud services, executing the approved logic and creating Nexsets as needed.
These agents work together to deliver a seamless, intuitive experience for users, automating tasks that would otherwise require significant manual effort and technical expertise.
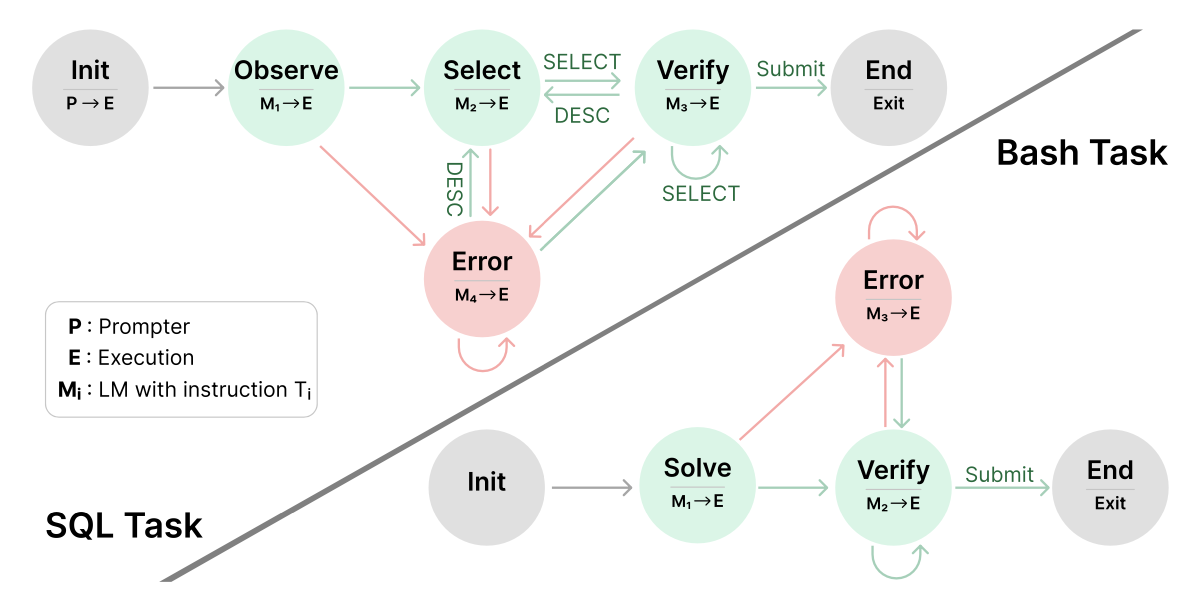
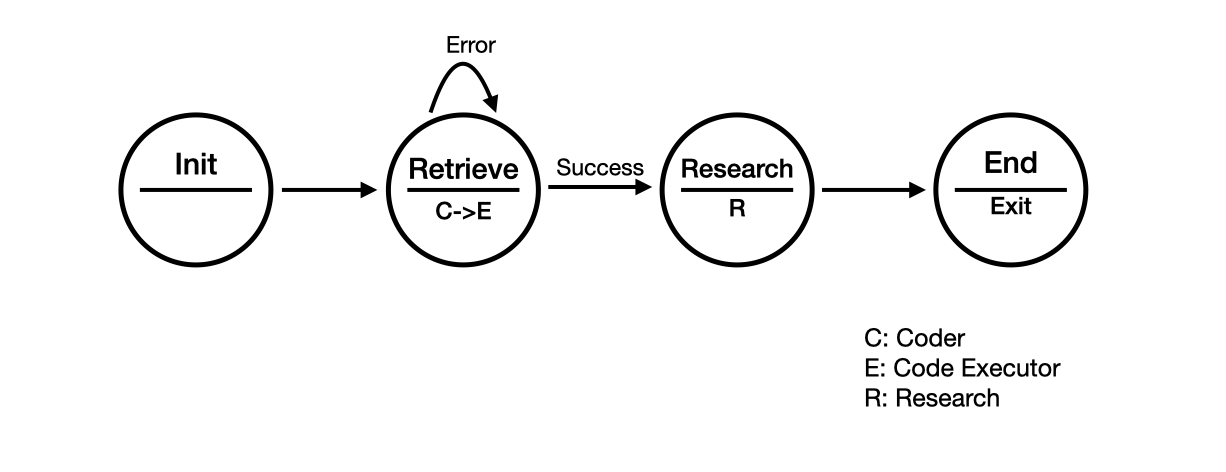
NOVA Architecture Diagram
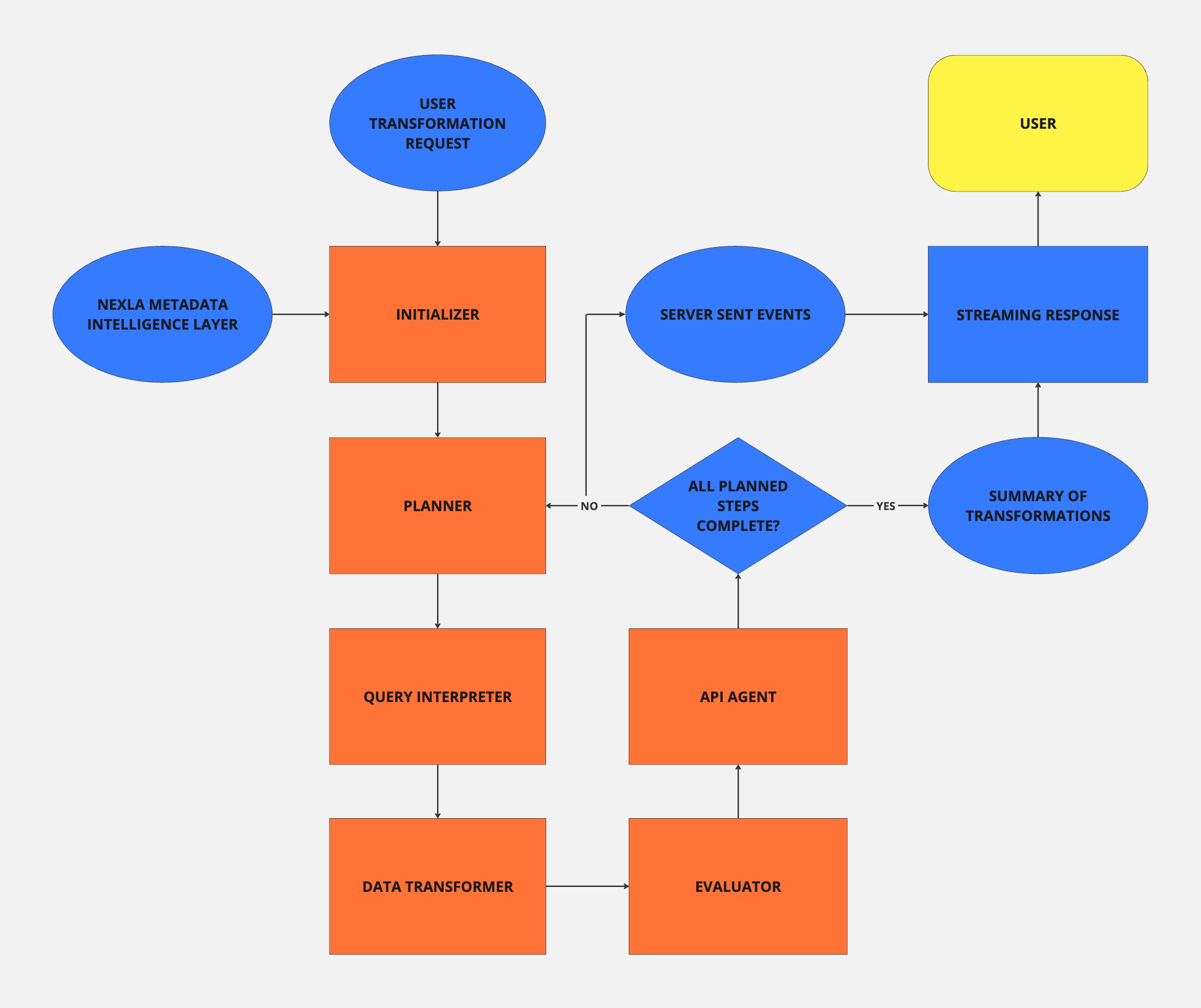
Using Server-Sent Events (SSE) in NOVA
An essential component of NOVA's architecture is the use of Server-Sent Events (SSE) to maintain real-time communication between the backend agents and the user interface. As the agents work through the various stages of query analysis, transformation, and execution, SSE allows NOVA to stream live updates back to the user. This ensures that users receive timely feedback on the status of their requests, especially for complex, multi-step processes. By leveraging SSE, we enhance the overall user experience, making interactions with NOVA feel more dynamic and responsive, while also providing insights into the ongoing data operations.
Conclusion: The Future of AI at Nexla
Our progress in developing NOVA has been significantly enhanced by utilizing the Autogen open-source library. Autogen’s powerful capabilities have been instrumental in helping us create intelligent agents that transform how users interact with data. As Autogen and similar technologies continue to evolve, we’re eager to explore new possibilities and innovations in the field of data automation.
Project NOVA and its features—Natural Language to Transforms and Natural Language to ELT—are just the beginning of what we believe is possible with Autogen. We’re already exploring new ways to expand these capabilities, making them even more powerful and user-friendly.
We invite you to explore these features and see firsthand how they can transform your workflows. Whether you’re a developer, analyst, or business leader, the possibilities are vast with Nexla. You can start your free trial to see how our solutions can work for you.
For any inquiries or further information, feel free to contact us.
















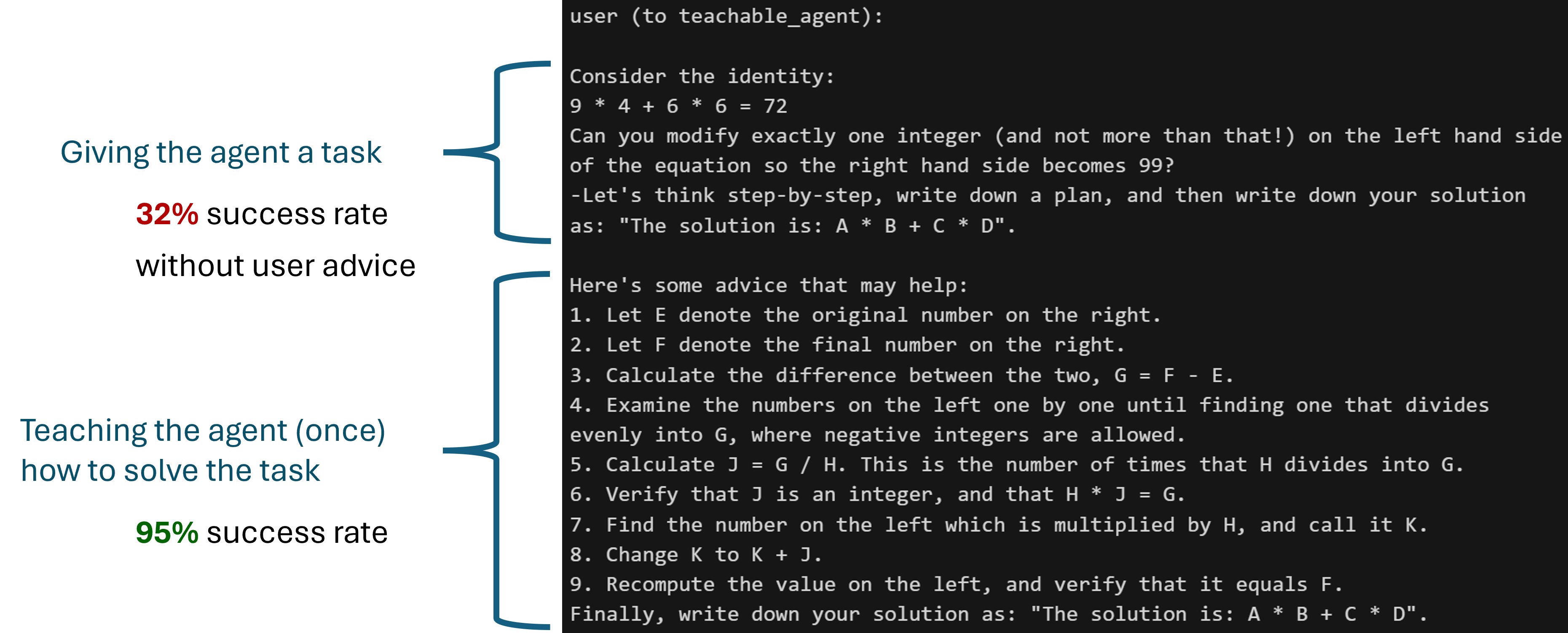 This feature works for GPTAssistantAgent (using OpenAI's assistant API) and group chat as well. One interesting use case of teachability + FSM group chat:
This feature works for GPTAssistantAgent (using OpenAI's assistant API) and group chat as well. One interesting use case of teachability + FSM group chat: